Diffusion Model 4 Protein
Inverse protein folding is challenging due to its inherent one-to-many mapping
characteristic, where numerous possible amino acid sequences can fold into a single,
identical protein backbone. This task involves not only identifying viable sequences
but also representing the sheer diversity of potential solutions. This article is the overview of the technology utilized by Graph Denoising Diffusion for Inverse Protein Folding.
ResNet

残差学习就是改变传统的网络结构,将层间传输的数据转换为F(x)+x的形式。优势在于梯度不会随着导数的相乘而快速趋近于0,使得网络在达到Plateau后继续下降收敛。

Transformer
序列转录模型,运用Attention机制,取得了全局信息的抽取效果,而且避免了RNN存在的诸如梯度消失和难以并行计算的缺点。
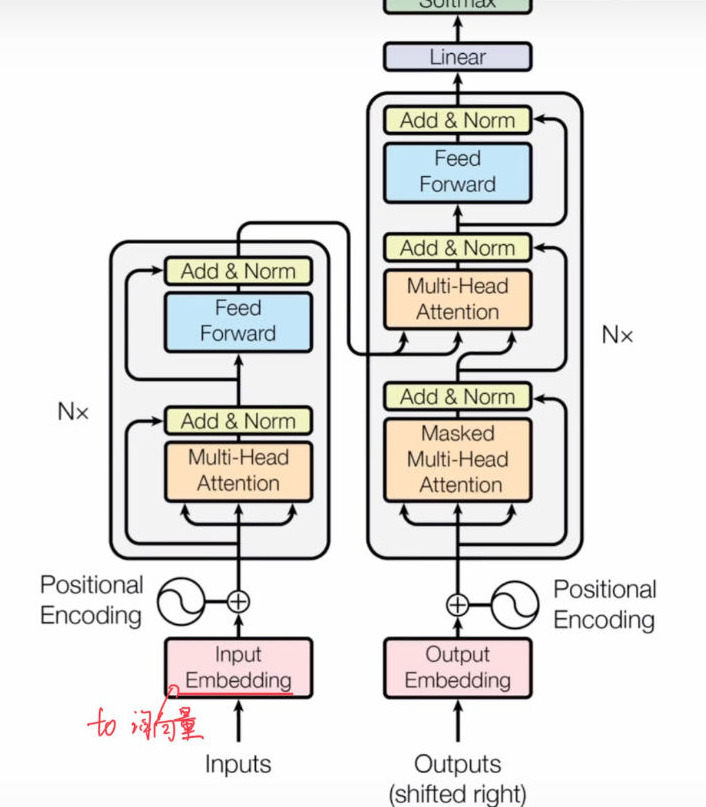
同样运用了Residual的链接方式和样本层面的layer norm,能够处理边长序列的样本信息。
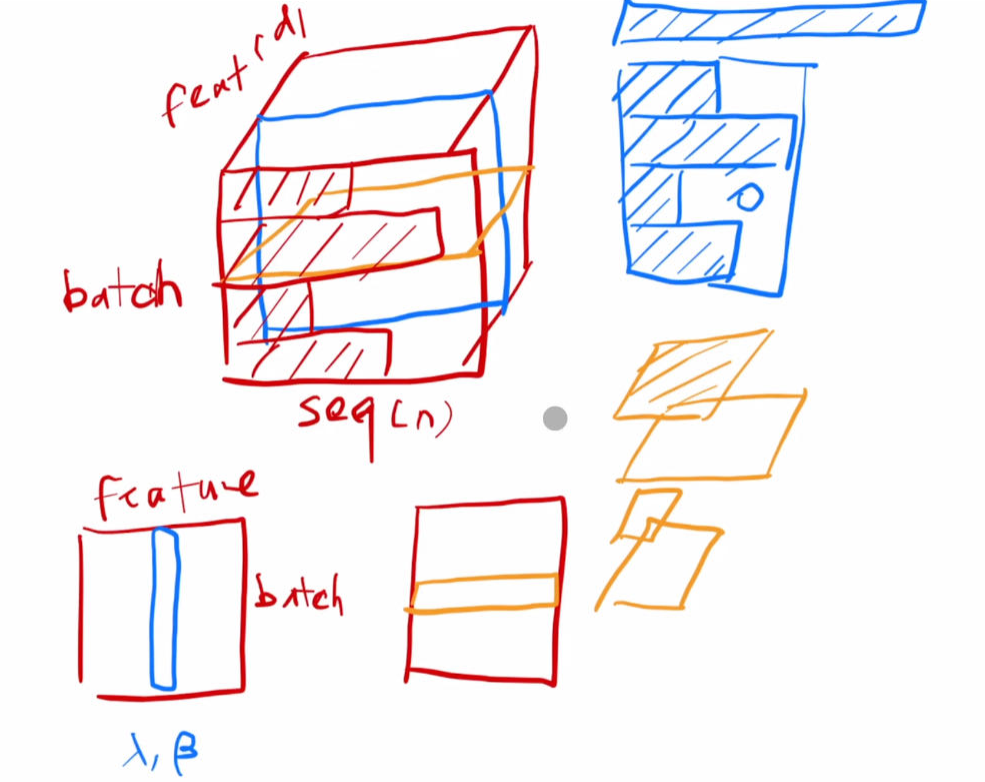
此外,1)还要注意decoder的Mask机制,以及类似条件概率的序列生成方式 。2)Attention无法取得序列的位置信息,所以需要对位置进行cos的编码,使得MLP层能够学习到顺序Info。
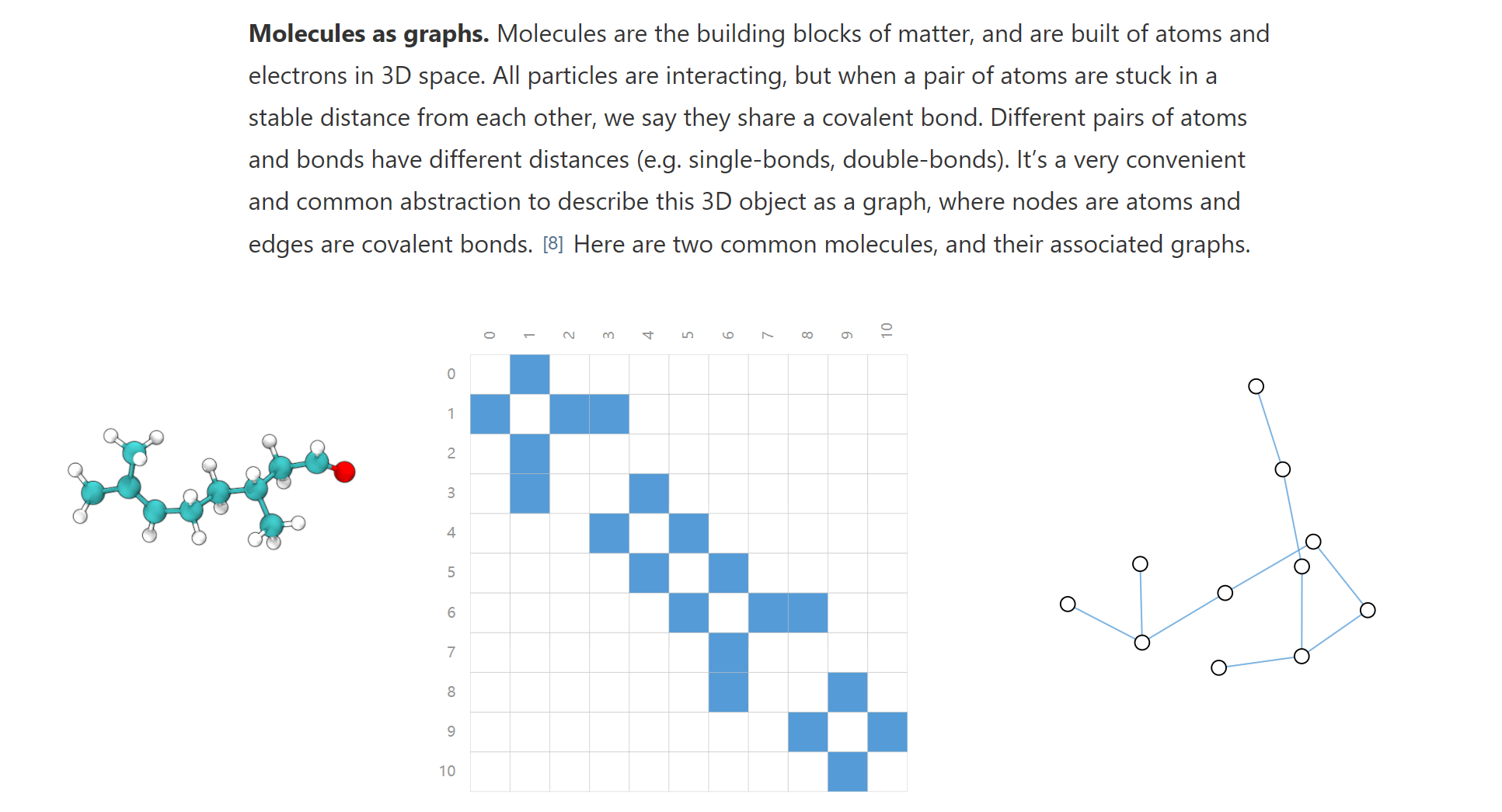
GNN
图神经网络利用的图这种数据结构intrinsically具有的强大特点,对于各种数据有这很好的结构化表示,详细介绍Distill:A Gentle Introduction to Graph Neural Networks (distill.pub)
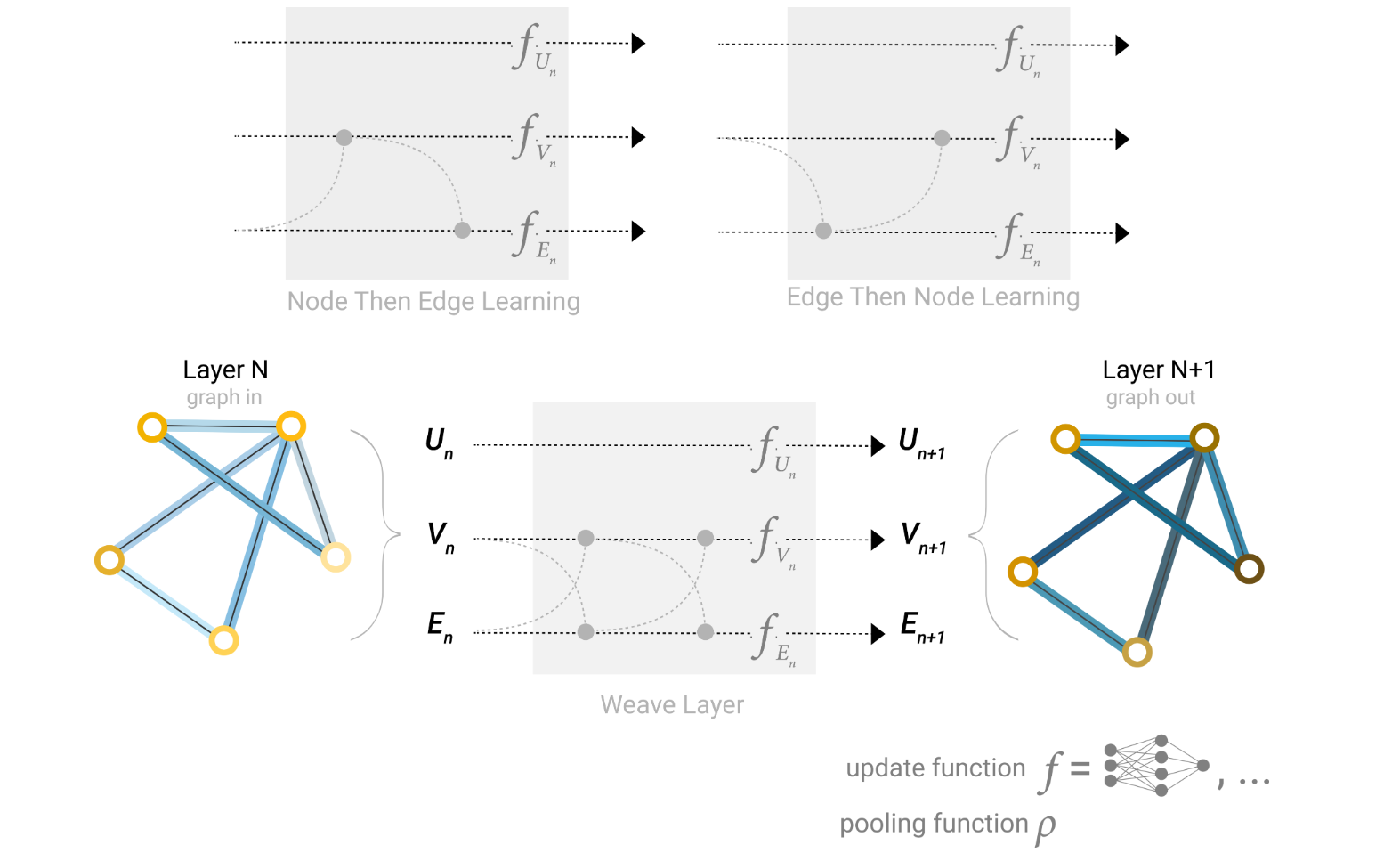
对于一个图数据,可以对顶点、边以及全局信息分别应用MLP进行学习,在通过数据相互传到的技巧,可以良好地学习到数据整体地特征。
What is GAN

GAN = Generative Adversarial Networks,生成对抗网络。即同时定义两个网络,生成器G和判别器D。通过博弈论新设计的目标函数,同时对两个网络进行对抗式的训练。最终达成的目的是使得G生产的图片非常趋近于Ground Truth的图片(图d),而D无法分辨,收敛到1/2:
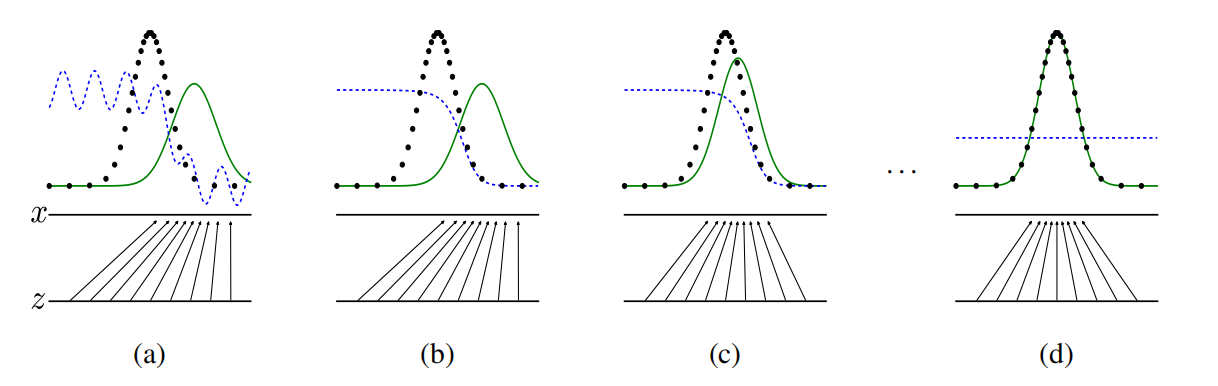
Diffusion Model Overview Via DALLE-2
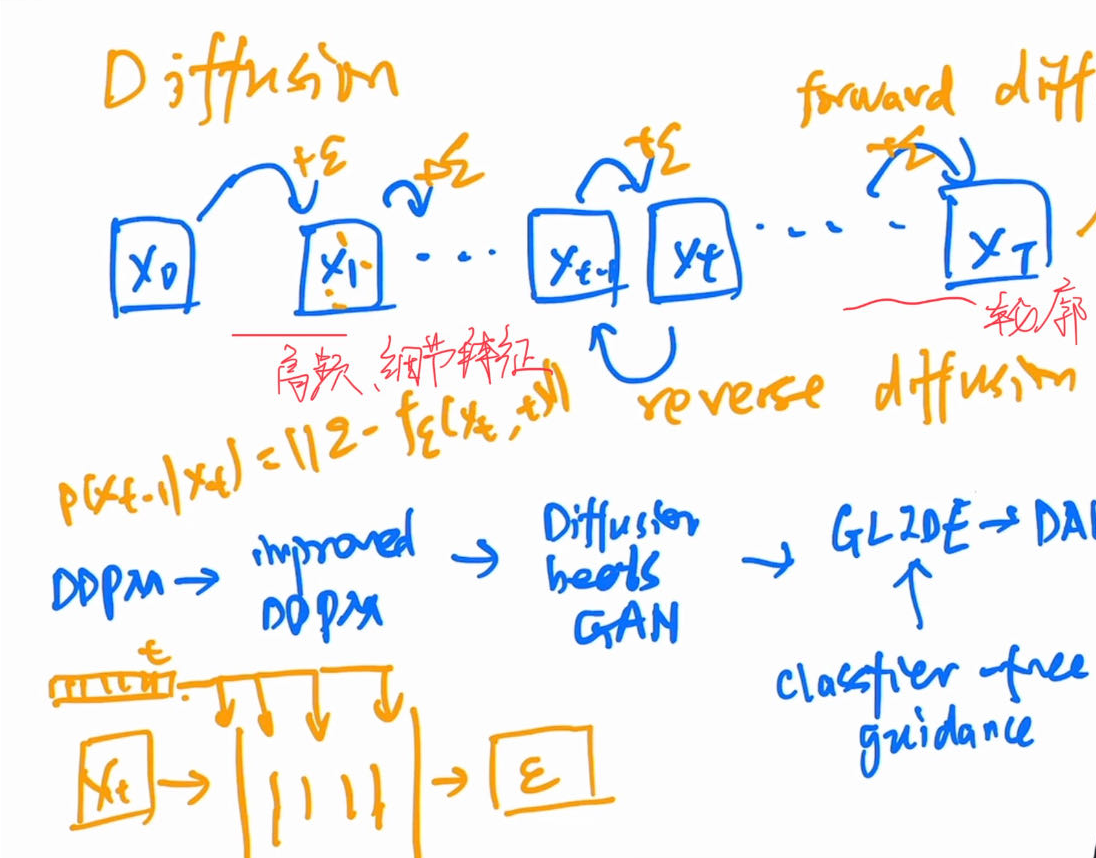
概率扩散模型, 实用的DDPM运用残差学习的思想, 在Reverse过程中, 不通过Xt到Xt-1直接得到,而是学习所加的噪声. 因为通过共享权重的U-Net来进行全局的预测,需要对位置进行 Time Embeding.
Classifier-Guided Diffusion
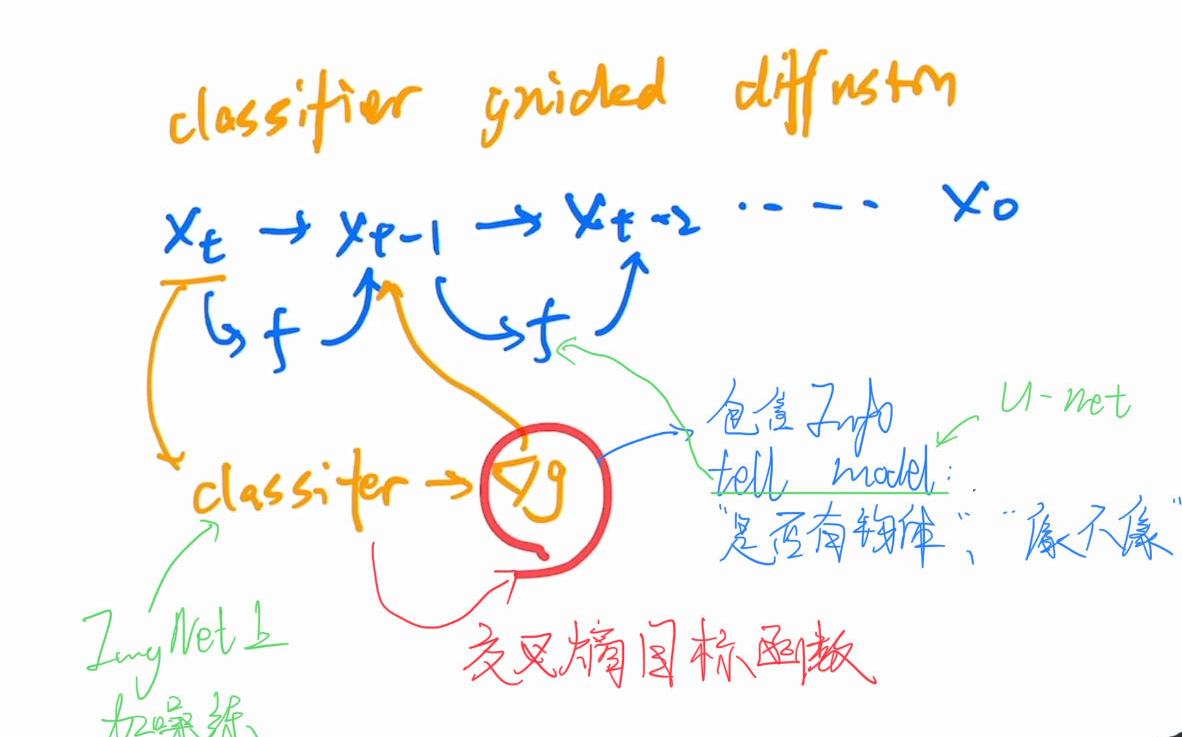
Diffusion Beats GAN中提出的方法,不仅可以用Classifier来指导训练, CLIP, LLM等都可以用来作为Guide函数.
Classifier-Free Diffusion

优化的目标函数变更. 通过学习有无条件生成X之间的Gap, 可以实现将即使在无条件下生成的图片转换成有条件Guide的图片.
AlphaFold2
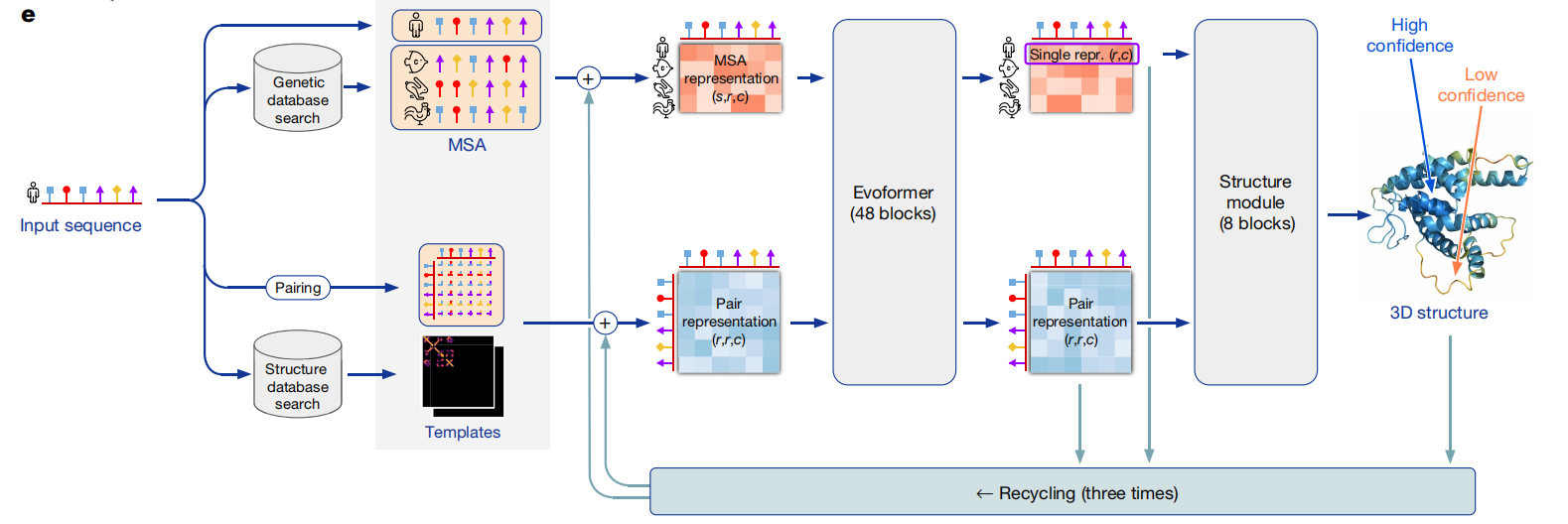
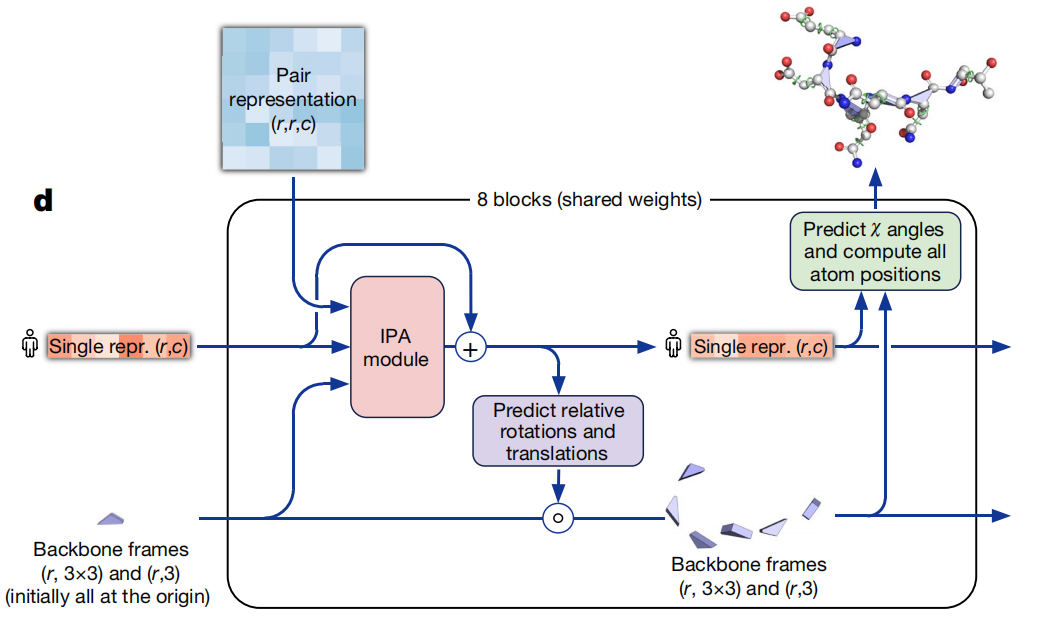

Nature补充材料: Highly accurate protein structure prediction with AlphaFold | Nature
Turnover number & DLKcat

底物 Substrate: Substrate refers to the specific molecule or molecules that an enzyme acts upon in an enzymatic reaction. Enzymes bind to their substrates at their active sites, which are specific regions of the enzyme’s structure that complement the shape and chemical properties of the substrate(s). This binding of the substrate to the enzyme’s active site forms an enzyme-substrate complex.
Protein Graph


DataSet
CATH: Protein Structure Classification Database at UCL, which conducts 151 million protein domains classified into 5,841 superfamilies. 使用wget方法下载.

Website: CATH: Protein Structure Classification Database at UCL (cathdb.info)
Protein Domain:
